
WG6 meeting in Leuven: Schedule and Abstracts
Programme
† Audience swapping time.
| Thursday Apr 4 | |
|---|---|
| 8h50 - 9h00 | Welcome & practical info |
| 9h00 - 10h15 † | HoTT talks |
| 10h20 - 10h45 | J. Chen & Kraus |
| 10h45 - 11h10 | Frey |
| 11h10 - 11h40 | 30 min break |
| 11h40 - 12h30 | Szamozvancev |
| 12h30 - 14h00 | 90 min lunch break |
| 14h00 - 14h25 | Felicissimo |
| 14h25 - 14h50 † | Lafont & Lamiaux & Ahrens |
| 14h55 - 15h20 | Tsampas |
| 15h20 - 16h00 | 40 min break |
| 16h00 - 16h50 | Zwart |
| 16h50 - 17h10 | 20 min break |
| 17h10 - 17h35 | Ceulemans & Nuyts & Devriese |
| 17h35 - 18h00 | Neumann |
| Friday Apr 5 | |
|---|---|
| 9h00 - 9h50 | L.-T. Chen |
| 9h50 - 10h45 | 55 min break |
| 10h45 - 11h10 | Loukanova |
| 11h10 - 11h35 † | Blazy & Herbelin & Letouzey |
| 11h40 - 12h05 | Poiret |
| 12h05 - 12h30 | Winterhalter |
| 12h30 - 14h00 | 90 min lunch break |
| 14h00 - 14h50 | Lennon-Bertrand |
| 14h50 - dinner | Collaborative time |
Invited talks
Liang-Ting Chen (Institute of Information Science, Academia Sinica, Taiwan): From Datatype Genericity to Language Genericity (Slides - Video)
Traditional language formalisation frameworks prioritise formalising and analysing ‘well-typed syntax’, which includes generic syntax signatures, terms, operations rooted in well-typed syntax, and associated substitution proofs. However, these frameworks only cover a small fraction of language design and implementation, leaving many concepts untouched. This talk explores insights from datatype-generic programming to illustrate the path towards language-generic programming. Specifically, we will showcase the isomorphism between extrinsic and intrinsic typing using McBride’s ornaments, generic bidirectional type synthesis, and some ongoing work.
Meven Lennon-Bertrand (University of Cambrige, UK): Towards a certified type theoretic kernel (Slides - Video)
Proof assistant kernels are a natural target for program certification: they are small, critical, and well-specified. Still, despite the maturity of type theory and software verification, we are yet to see a certified Agda, Coq or Lean. In this talk, I will give an overview of the current state of the landscape around this goal, present two complementary lines of work advancing towards it, and try and explain why it is still evading us. The first line, MetaCoq, is a large scale endeavour, broadly aiming at manipulating Coq terms and derivations inside Coq, in particular developing a certified type-checker for a very significant fragment of Coq. The second is concerned with formalised logical relations, the standard tool of the trade to deal with normalisation proofs and extensionality equations.
Dmitrij Szamozvancev (University of Cambrige, UK): Functorial models of scope-safe syntax (Slides - Video)
Computer implementation and formalisation of syntaxes with variable binding regularly encounters difficulties with the representation of variables, definition of substitution, and verification of standard meta-syntactic properties. Among the variety of approaches developed over the past 40 years, the functorial approach – encoding syntax as a functor on scopes – proved to be robust and efficient, possessing strong categorical properties that result in clean and well-behaved formalisations. This talk will give an overview of the monadic and presheaf approaches, detailing ongoing work to adapt the latter to practical dependently-typed settings.
Maaike Zwart (IT University of Copenhagen, Denmark): What monads can and cannot do with a bit of extra time (Slides - Video)
The delay monad provides a simple way to introduce general recursion in type theory. Combining this monad with other monads then allows us to write programs in type theory that use a wide range of computational effects. In this talk I will look at two ways of combining the delay monad with monads that can be described by higher inductive types (HITs). The first way is via a distributive law, which describes the interaction between the two effects. But… such distributive laws do not always exist. In fact, I will show that there is no distributive law for combining the delay monad with the finite powerset monad (modelling non-determinism) or the finite distribution monad (modelling probability). We therefore also look at a second way, via a free combination with no interaction between the two effects. This still gives a rich language allowing us to reason about non-determinism and probabilistic effects in the presence of recursion.
Contributed talks
Vincent R.B. Blazy, Hugo Herbelin & Pierre Letouzey (Université Paris Cité): Explicit Cumulativity in CC_ω (Slides - Video)
In usual CIC (or even CC_ω), because of the cumulativity of the hierarchy of universes, there is no unicity of the sort of a type: a type known to be a proposition (i.e. inhabiting Prop) is also a type (i.e. inhabiting Type_i for some nonzero natural number i). This phenomenon is called subsumption. Cumulativity is then a form of subsumptive, implicit subtyping between universes that somewhat introduces a lack of control in the typing (in particular, the sorting) information in CIC, and precludes this way a proper detailed analysis of the structure of their hierarchy.
But recent years have shown blockages caused precisely by a lack of understanding of the fine structure of universes. This happened on a number of subjects which are all initial motivations for this work, some of them fundamental such as the construction of set-theoretic models and the role of impredicativity, but also for other directly applied subjects such as program extraction and the ability to reason modulo η-expansion in Coq. For instance, the Coq extraction prunes the parts of a proof term which are propositional to keep only the informative ones (inhabiting types), so its process would benefit of that finer control of which types actually come from Prop by subsumption in the current implicit Coq, to get more optimal.
This talk will be about our attempt - namely CC_ω^sub - of explicitation of this subtyping between universes in a coercive way, for the moment in CC_ω alone (with untyped conversion and sorted domains & typing judgements). For that we keep track of the coercions from universes to others that are successively followed along typing derivation trees, and as much on the propositions and types inhabiting those universes than on their own inhabitants, that are then themselves coerced in parallel with their type. This means that our explicit subtyping system extends structurally to Π-types - covariantly and contravariantly - and to terms of the types coerced into bigger universes. For now again, CC_ω^sub has a syntactic (subject) reduction on terms decorated with coercions, congruent conversion rules with restricted η and an equivalent syntactic extensionality for coerced functions. It also takes advantage of some usual good properties, several commutation and lifting lemmas. We constructed as well two algorithms for synthesizing respectively relevant subtyping marks, and explicitly well-typed decorations of implicitly well-typed terms (that is, portions of computable interpretations of CC_ω into CC_ω^sub, dual to the interpretation the other way around that - almost - merely erases all coercions).
Joris Ceulemans, Andreas Nuyts, Dominique Devriese (KU Leuven): Admissibility of Substitution for Multimode Type Theory (Slides - Video)
Multimode Type theory (MTT) [Gratzer et al., 2020] is a generic type theory that can be instantiated with an arbitrary mode theory to model features like parametricity, cohesion and guarded recursion. However, the presence of modalities in MTT significantly complicates the substitution calculus of this system. Moreover, MTT’s syntax has explicit substitutions with an axiomatic system – not an algorithm – governing the connection between an explicitly substituted term and the resulting term in which variables have actually been replaced. So far, admissibility of substitution for MTT has only been proved as a consequence of normalisation via normalisation by evaluation. In this talk, we will present a proof of admissibility of substitution for MTT that is completely separated from normalisation. To this end, we introduce Substitution-Free Multimode Type Theory (SFMTT): a formulation of MTT without explicit substitutions, but for which we are able to give a structurally recursive substitution algorithm, suitable for implementation in a total programming language or proof assistant. On the usual formulation of MTT, we consider σ-equality, the congruence generated solely by equality rules for explicit substitutions. There is a trivial embedding from SFMTT to MTT, and a converse translation that eliminates the explicit substitutions. We prove soundness and completeness with respect to σ-equivalence and thus establish that MTT with σ-equality has computable σ-normal forms, given by the terms of SFMTT.
Joshua Chen, Nicolai Kraus (University of Nottingham): Constructing inverse diagrams in homotopical type theory (Slides - Video)
Inverse diagrams, i.e. functors indexed by inverse categories, feature prominently in both the metatheory and applications of homotopical type theory (which we take to include MLTT without UIP, alongside the various incarnations of homotopy type theory). Besides their well known appearances as building blocks for higher categories and presheaf models of HoTT, they also give new model constructions (Shulman 2013, Kapulkin and Lumsdaine 2021), (homotopy) canonicity and parametricity results (Shulman 2013), and presentations of higher categorical structures with strict composition (Kock 2005).
The majority of the above results are developed in a standard mathematical metatheory, assuming proof-irrelevant equality. We move the fundamental constructions of inverse diagrams and matching objects of Reedy fibrations into a constructive setting without UIP, by describing a construction of inverse diagrams in wild categories with families in HoTT. We develop some theory of wild cwfs, which form a common generalization of set-based and infinity-cwfs and thus include as examples both the syntax and the “standard” universe model. We then construct the matching object as a wild functor from cosieves in sufficiently nice inverse categories to categories of contexts of wild cwfs. This sets the stage for further development of an internalized metatheory of HoTT as well as investigations into the existence of semisimplicial types in plain HoTT.
Thiago Felicissimo (Inria/LMF/Deducteam): Generic bidirectional typing for dependent type theories (Slides - Video)
Bidirectional typing is a discipline in which the typing judgment is decomposed explicitly into inference and checking modes, allowing to control the flow of type information in typing rules and to specify algorithmically how they should be used. Bidirectional typing has been fruitfully studied and bidirectional systems have been developed for many type theories. However, the formal development of bidirectional typing has until now been kept confined to specific theories, with general guidelines remaining informal. In this work, we give a generic account of bidirectional typing for a general class of dependent type theories. This is done by first giving a general definition of type theories (or equivalently, a logical framework), for which we define declarative and bidirectional type systems. We then show, in a theory-independent fashion, that the two systems are equivalent. This equivalence is then explored to establish the decidability of typing for weak normalizing theories, yielding a generic type-checking algorithm that has been implemented in a prototype and used in practice with many theories. This implementation can be found at https://github.com/thiagofelicissimo/BiTTs.
Jonas Frey (Carnegie Mellon University): The shape of contexts (Slides - Video)
Contexts x_1:A_1,...,x_n:A_n in simple type theory can be viewed as “flat”,
since the variable declarations don’t depend on each other and can be permuted.
In dependent type theory, the general form of contexts is
(x_1:A_1, x_2:A_2(x_1), ...,x_n:A_n(x_1,...,x_{n-1}))
with a linear dependency chain between the variable declarations:
However, the specific contexts occuring in practice are not always totally
ordered. For example, in the the context (x y:O, f:A(x,y)) the first two
variables are not interdependent.
So maybe we should allow finite posets as shapes of contexts? It turns out to be better to use an even more general class of structures: finite direct categories, i.e. finite categories which have no nontrivial isomorphisms and endomorphisms.
FDCs were introduced by Makkai [1] as part of his notion of “First order logic with dependent sorts”, but the perspective on FDCs proposed in this talk is somewhat different since FDCs are not used to represent dependency structures of theories, but of contexts.
In the talk I will explain why FDCs seem to provide a good abstract notion of “shape” for contexts, that the category of FDCs and discrete fibrations forms a coclan, and how to derive a notion of dependent algebraic theory from these ideas which is very close to Chaitanya Leena Subramaniam’s “dependently typed theories”.
More details can be found in notes of a recent seminar talk on the same topic [2].
[1] https://www.math.mcgill.ca/makkai/folds/foldsinpdf/FOLDS.pdf [2] https://github.com/jonas-frey/pdfs/blob/master/cmu-hott-seminar-2023-10-06.pdf
Ambroise Lafont, Thomas Lamiaux, Benedikt Ahrens (École Polytechnique, ENS Saclay, Delft University of Technology): Initial semantics for polymorphic type systems (Slides)
Initial semantics (IS) as a concept aims to characterize (higher-order) programming languages as initial objects in well-chosen categories of “models”. Considering programming languages categorically, as appropriate initial models, has many advantages. By choosing models of a programming language to be appropriate algebras, models provide us with a mathematical abstraction of the syntax of the language, including variable-binding constructions. Indeed, in a model, the terms and the constructors of the language are represented as abstract categorical notions that capture their properties. This enables us to manipulate the language by only considering these categorical notions, without having to constantly deal with its syntax and implementation, in particular with the implementation of binders. Furthermore, the initiality of the model provides us with an abstract recursion principle. Indeed, informally, being initial for a model means that among the models that abstract syntax, it is the “smallest” one, i.e. that it is “embedded” in any other model. By unfolding the definitions, this provides us with a recursion principle in the same categorical terms as the ones used for the abstract syntax, thus enabling us to reason by recursion on the abstract syntax without having to deal with any underlying implementation. Initial models can therefore abstract the syntax with its recursion principle.
Initial semantics for untyped and simply-typed languages have been developed in different lines of work, by different groups of researchers. In one line of work, Fiore and collaborators have developed IS based on the notion of Sigma-monoid. In another line of work, André Hirschowitz, Maggesi, Ahrens, Lafont, and Tom Hirschowitz have developed initial semantics based on modules over monads. Moreover, the different approaches have been extended to incorporate notions of term equations or reductions between terms into the semantics. A detailed overview of these lines of work, and how they are connected, is given in [3].
For polymorphic type systems, the work is less developed. Hamana [2] and Fiore and Hamana [1] have proposed initial semantics for polymorphic type systems, like System F or System Fω, based on presheaf categories GU → Set. The category GU is built as a Grothendieck construction, and is specific to each language. An object of GU is a triple (n, Gamma, t), such that n a number of type variables, Gamma is a context of variables whose types may contain n type variables, and t is another type with n free type variables. Terms are then, in particular, modeled as functors GU → Set that, given (n,Gamma,t), return the set of well-typed terms of type t in context (n,Gamma).
In our work in progress, we aim to first reformulate, then extend, the work by Hamana and Fiore. Specifically, the reformulation we are working on is based on a monoidal category with a particularly simple monidal structure. Within that category, we develop a notion of signature and model of a signature using the vocabulary of modules over monoids. We anticipate that the reformulation will be instructive and better our understanding of polymorphic type systems. Furthermore, we aim to extend insights from the work on simply-typed initial semantics to the polymorphic setting, in particular, the translation between polymorphic languages and the theory of operational semantics.
- [1] Marcelo Fiore and Makoto Hamana, Multiversal Polymorphic Algebraic Theories, LICS 2013, pp. 520-529, https://www.cl.cam.ac.uk/~mpf23/papers/Algebra/mpat.pdf
- [2] Makoto Hamana, Polymorphic Abstract Syntax via Grothendieck Construction, FoSSaCS 2011, pp. 381-395, https://link.springer.com/content/pdf/10.1007/978-3-642-19805-2_26.pdf
- [3] Thomas Lamiaux and Benedikt Ahrens, An Introduction to Different Approaches to Initial Semantics, https://arxiv.org/abs/2401.09366
Roussanka Loukanova (Department of Algebra and Logic, Institute of Mathematics and Informatics, Bulgarian Academy of Sciences): Relations between let-Terms of Lambda-Calculus and where-Terms of Type-Theory of Recursion (Slides - Video)
I shall present the extended Type-Theory of Recursion (TTR) introduced in [3,1,2]. I demonstrate the role of the canonical forms of the TTR terms for their algorithmic and denotational semantics by examples of translations of natural language expressions into TTR.
TTR provides type-theoretic algorithmic semantics of natural and formal languages by generalizing the let-expressions of lambda-calculus, e.g., in the formal language LCF, by Dana S. Scott and Gordon Plotkin. In [1], I provide a mathematical proof that Scott let-terms are not algorithmically equivalent with the where-recursion terms of TTR. They remain denotationally equivalent. I shall present the major points of the theorem.
Dana Scott has encouraged me with a high assessment of [1]. But, he also presented me with an important question, which encourages further development of TTR. I shall open the Scott question by giving new lines of initiated and future work on TTR.
References
[1] Loukanova, R.: Logic Operators and Quantifiers in Type-Theory of Algorithms. In: D. Bekki, K. Mineshima, E. McCready (eds.) Logic and Engineering of Natural Language Semantics, pp. 173–198. Springer Nature Switzerland, Cham (2023). URL https://doi.org/10.1007/978-3-031-43977-3_11
[2] Loukanova, R.: Restricted Computations and Parameters in Type-Theory of Acyclic Recursion. ADCAIJ: Advances in Distributed Computing and Artificial Intelligence Journal 12(1), 1–40 (2023). URL https://doi.org/10.14201/adcaij.29081
[3] Moschovakis, Y.N.: A Logical Calculus of Meaning and Synonymy. Linguistics and Philosophy 29(1), 27–89 (2006). URL https://doi.org/10.1007/s10988-005-6920-7
Jacob Neumann (University of Nottingham): Towards Modal SOGATs (Blackboard - Video)
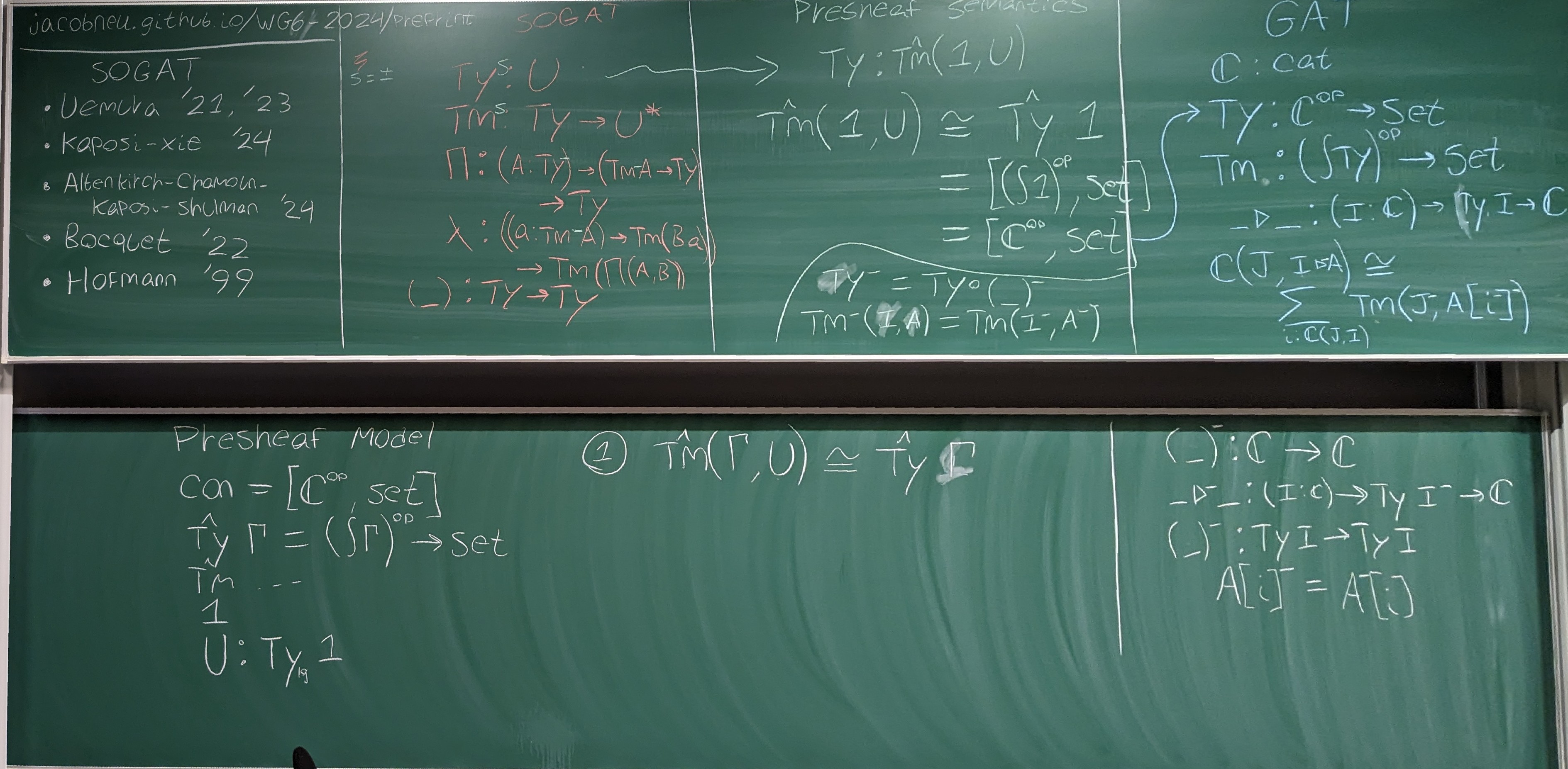{kind=link}
One notable shortcoming of standard semantics of type theory, such as categories with families (CwFs), is that each new type- and term- former must be introduced alongside laws stipulating that it is stable under substitution. When trying to give semantics for fully-featured type theories, such as Homotopy Type Theory, this can become quite tedious. This shortcoming can be overcome by working in a higher-order abstract syntax, which encodes variable binding as metatheoretic functions and makes stability under substitution implicit. Moreover, higher-order abstract syntax can be given semantics in presheaf categories [Hofmann 1999], whose category-theoretic properties are well-understood. Such approaches have recently been the focus of investigation in the form of second-order generalized algebraic theories, or SOGATs [Uemura 2019; Bocquet, et al. 2023], and in the development of higher observational type theory [Shulman 2022; Altenkirch, et al. 2024].
However, higher-order abstract syntax works by ‘abstracting’ away from explicit reference to contexts and substitutions. This means it is not obvious how to deploy these tools in the study of type theories with ‘modalities’, that is, explicit operations on contexts. This includes, for example, many varieties of directed type theory (e.g. [Harper and Licata 2011]) and modal type theory [Gratzer, et al. 2020]. In this talk, I describe some of my recent work (joint with Thorsten Altenkirch) to address this concern. In particular, I’ll discuss the category model of directed type theory (which is the directed analogue of the groupoid model of type theory [Hofmann and Streicher 1995]) and show how its two key modalities—opposite and core—can be made “abstract enough” to be expressible in higher-order abstract syntax. This will hopefully provide a roadmap for doing the same for arbitrary modalities, permitting us to combine these two exciting avenues of research.
Josselin Poiret (Nantes Université and Inria, Galinette Team): A multiverse type theory (Slides - Video)
Recent years have seen a flourishing of different type theories based on CIC or Martin Löf Type Theory, purpose-built for domain-specific problems: Homotopical Type Theory and Cubical Type Theory, definitionally irrelevant propositions, Guarded Type Theory, etc. Each of these systems offer tangible advantages to their users, but this situation also creates fragmentation as one has to choose which of these flavors will suit their project the most, eschewing all others in the process.
We propose a multiverse type theory, in which multiple type theories live at different sorts and interact in a controlled manner, letting users rely on the features they prefer while being able to interface with other systems. This can be seen as a generalization of the Type/Prop/SProp distinction in Coq, 2 Level Type Theory or Reasonably Exceptional Type Theory. We want to explore how different meta-theoretical properties of this composite type system can be abstractly obtained from its parts in a modular manner, all formalized in a proof assisant. We also hope that this new system will lead to more formal mechanizations of internal arguments, such as used by the novel techniques for normalization.
Stelios Tsampas (Friedrich-Alexander-Universität Erlangen-Nürnberg): Logical Relations in Higher-Order Mathematical Operational Semantics (Slides - Video)
Logical relations constitute a key method for reasoning in higher-order languages. They are usually developed on a per-case basis, with a new theory required for each variation of the language or of the problem setting. In recent work, we have introduced general constructions of (step-indexed) logical relations at the level of Higher-Order Mathematical Operational Semantics (HO-MOS), a highly parametric categorical framework for modeling the operational semantics of higher-order languages. Furthermore, we have developed efficient principles that simplify reasoning on logical relations for languages specified in the HO-MOS framework. As an example, we prove that, for languages whose weak operational model forms a lax bialgebra, one can construct a logical relation that is automatically sound for contextual equivalence. Our abstract theory is shown to instantiate to point-free languages in the style of combinatory logic and lambda-calculi with both simple and recursive types. This is joint work with Sergey Goncharov, Henning Urbat, Stefan Milius, Lutz Schröder and Alessio Santamaria.
Théo Winterhalter (Inria Saclay): Dependent ghosts enjoy reflection for free (Slides - Video)
I will present ghost type theory (GTT) a dependent type theory extended with a new universe for ghost data that can safely be erased when running a program (typically at extraction) but which is not proof irrelevant like with a universe of (strict) propositions. Instead, ghost data carry information that can be used in proofs or to discard impossible cases in relevant computations. Casts can be used to replace ghost values by others that are propositionally equal, but crucially these casts can safely be ignored for conversion. I will give a syntactical model of GTT using a parametricity translation in the style of Pédrot and Tabareau’s Failure is Not an Option. This model establishes consistency of the theory as well as a form a type former discrimination. I further extend GTT to support equality reflection and show that we can eliminate its use without the need for the usual extra axioms of function extensionality and uniqueness of identity proofs.